Not All Layers Are Equal:
Mixed-precision quantization for weights and KV cache on Apple Silicon.
Some transformer layers are up to 56× more sensitive to quantization than others. Per-layer KL-divergence measurement is the foundation for mixed-precision quantization on Apple Silicon. The standard approach is uniform 4-bit: every layer gets the same treatment. mlx-optiq instead measures which layers actually need precision and which don't, then allocates the bit budget where it matters.
The KV cache, which gets less attention, becomes the dominant memory cost at long contexts, where uniform quantization breaks down.
This is the sensitivity-driven quantization pipeline we built for MLX. Most of mlx-optiq grew out of this work.
The setup
We worked with Qwen3-0.6B-base on an M3 Max, using Apple's MLX framework. The approach is straightforward: for each layer, temporarily quantize it, run calibration data (WikiText-2) through the full model, and measure the KL divergence of the output logits against a reference. This gives a per-layer sensitivity score at each candidate bit-width.
A greedy knapsack algorithm then assigns bits (more to sensitive layers, fewer to robust ones) to hit a target average bits-per-weight.
We tested this on three model types: LLMs (Qwen3-0.6B), vision-language models (Qwen3-VL-2B), and speech recognition (Qwen3-ASR-0.6B).
Result 1: weight quantization, +17 pp on math reasoning
With per-layer 4 / 8-bit allocation at 4.5 average bits-per-weight, the mixed-precision model scores 51 % on GSM8K (100-question math reasoning) compared to 34 % for uniform 4-bit: a 17-percentage-point improvement at only 11 % more model size.
| Model | Size | BPW | Perplexity | GSM8K |
|---|---|---|---|---|
| Uniform 4-bit | 320 MB | 4.0 | 19.2 | 34 % |
| Mixed 4 / 8-bit | 355 MB | 4.5 | 17.4 | 51 % |
| Mixed 3 / 4-bit | 266 MB | 3.5 | 32.7 | 9 % |
The sensitivity analysis shows a clear structure: lm_head has 8× the sensitivity of the median layer, the last transformer block layers go up to 6.8×, and early layers with downstream amplification reach 10.4×. Query / key projections sit at 1.0×, safely quantized to minimum bits.
The mixed-precision allocation dominates the entire Pareto frontier between uniform 3-bit and uniform 8-bit. At every model size, it matches or beats the uniform baseline.

Result 2: KV cache, the hidden memory problem
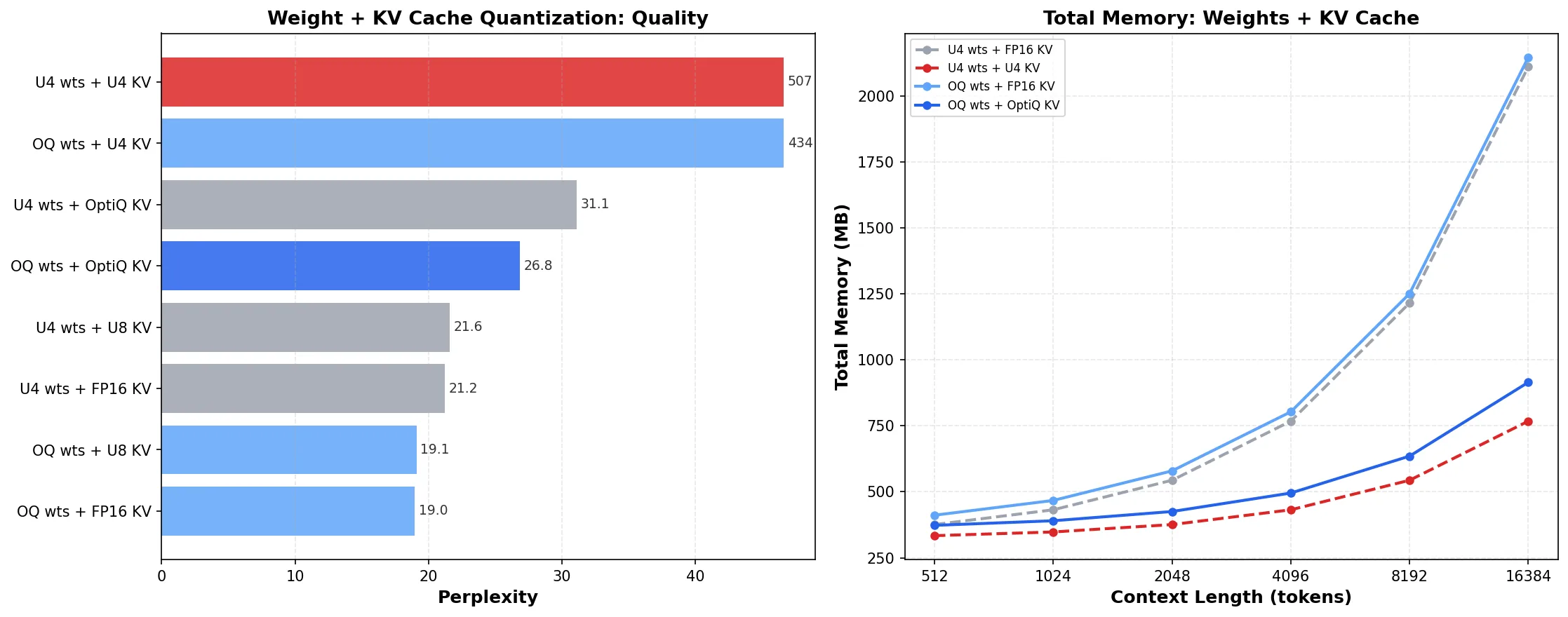
The KV cache stores key / value projections for all past tokens during generation. For Qwen3-0.6B at 4 K context, the FP16 KV cache is 448 MB: already 140 % of the model weights (320 MB). At 16 K context it's 1.8 GB, or 5.6× the weights.
MLX supports uniform KV cache quantization, but when we measured per-layer sensitivity, we found Layer 0's KV cache is 56× more sensitive than average. Uniform 4-bit KV doesn't know this.
The result is catastrophic:

| KV Config | Perplexity | KV memory savings |
|---|---|---|
| FP16 (reference) | 21.2 | — |
| Uniform 8-bit | 21.6 | 44 % |
| Mixed 5-bit | 31.1 | 62 % |
| Uniform 4-bit | 507.5 | 69 % |
Uniform 4-bit KV quantization sends perplexity from 21 to 507. The fix: keep 7 sensitive layers (out of 28) at 8-bit. This costs only 7 % more KV memory than uniform 4-bit but gives 16× better quality.
The per-layer sensitivity chart shows why. Most layers are robust, but Layer 0 is an extreme outlier that must stay at higher precision.

Result 3: the full stack, 57 % memory savings at 16 K context
Combining mixed-precision weights and mixed-precision KV cache, the savings compound at long contexts:
| Context length | Default (U4 + FP16 KV) | Full mixed | Savings |
|---|---|---|---|
| 4 K tokens | 768 MB | 495 MB | 35 % |
| 16 K tokens | 2,112 MB | 915 MB | 57 % |
| 32 K tokens | 3,904 MB | 1,475 MB | 62 % |
At 16 K context, mixed-precision saves 1.2 GB. On a base MacBook with 8 GB unified memory, this is the difference between fitting and not fitting.

KV cache sensitivity also depends on weight quantization. Different weight bit-widths produce different KV sensitivity profiles, and 10 of 28 layers get different KV allocations depending on the weight quantization. You can't just measure KV sensitivity on the FP16 model and call it done.
Result 4: works across modalities
The same approach works for vision-language and speech models:
- Qwen3-VL-2B: Mixed-precision recovers 32 % of the quantization accuracy gap on AI2D diagram understanding (41 % vs 35 % for uniform 4-bit) while being 25 % smaller. 85 of 104 vision encoder layers need 8-bit, while 195 of 197 language model layers are safe at 4-bit.
- Qwen3-ASR-0.6B: Mixed-precision reduces output divergence by 51.5 % vs uniform 4-bit on speech recognition, with WER improvement on LibriSpeech.
What we learned
The most sensitive layers are at the boundaries: first / last transformer blocks, lm_head, and embedding layers. Middle MLP layers are consistently robust.
At long contexts, the KV cache dominates total memory. Quantizing weights while leaving the KV cache in FP16 misses the biggest cost. Uniform 4-bit KV fails badly. It looks like it saves memory (69 % reduction) until you check quality and find it's completely broken.
Weight quantization and KV cache quantization aren't independent. The same model with different weight precision has different KV sensitivity profiles. Joint optimization over both gives better results than optimizing each in isolation.
Static rules (like "keep first and last layer at high bits") get the direction right but miss the magnitude. Layer 0's KV cache is 56× more sensitive, not 2×.
pip install mlx-optiq. Browse the 12 pre-built quants or read the methodology docs for the productionized story.