Measurements · Apple M3 Max 36 GB
Benchmarks: quality, speed, retrieval.
Three axes — weight quantization quality on GSM8K, KV-cache serving throughput at 64 k context, and TurboQuant rotated-space retrieval accuracy. All numbers are reproducible from the CLI and dataset listed in each section.
01 Weight quantization quality
mlx-optiq vs uniform 4-bit on GSM8K.
200-sample subset, 3-shot CoT prompt, identical sampling, identical chat-template handling.
LLM quality — GSM8K · 200 samples
| Model | Uniform-4 | mlx-optiq-4 | Delta |
|---|---|---|---|
| Qwen3.5-0.8B | 11.5% | 27.0% | +15.5pp |
| Qwen3.5-2B | 48.5% | 48.0% | −0.5pp |
| Qwen3.5-4B | 79.5% | 81.5% | +2.0pp |
| Qwen3.5-9B | 90.0% | 90.0% | 0.0pp |
| Qwen3.6-27B | 94.0% | 95.0% | +1.0pp |
| Qwen3.5-35B-A3B | 89.5% | 89.5% | 0.0pp |
| gemma-4-e2b-it | 5.5% | 13.0% | +7.5pp |
| gemma-4-e4b-it | 23.5% | 55.5% | +32.0pp |
| gemma-4-26B-A4B-it | 92.0% | 94.0% | +2.0pp |
| gemma-4-31B-it | 96.0% | 96.0% | 0.0pp |
Pattern
mlx-optiq's wins grow with how far uniform 4-bit degrades the model. On saturated benchmarks (Qwen3.5-9B at 90%), there's nothing to recover. On models that uniform 4-bit nearly breaks (gemma-4-e4b at 23.5%), recovery is dramatic — +32 points to 55.5%.
02 KV cache serving
Mixed-precision KV at 64 k tokens.
Apple M3 Max 36 GB. 64,000-token English prose prompt, streaming 500 output tokens. Comparing stock mlx_lm.server (fp16 KV) vs optiq serve --kv-config (per-layer sensitivity-guided KV quantization).
Decode tok/s at 64k
| Model | fp16 TTFT | fp16 decode | Mixed TTFT | Mixed decode | Decode speedup |
|---|---|---|---|---|---|
| Qwen3.5-0.8B | 34.5s | 47.2 tok/s | 40.5s | 42.4 tok/s | −10% |
| Qwen3.5-2B | 82.8s | 27.9 tok/s | 161.7s | 41.8 tok/s | +50% |
| Qwen3.5-4B | 165.8s | 8.1 tok/s | 252.0s | 13.1 tok/s | +62% |
| Qwen3.5-9B | 214.8s | 20.7 tok/s | 163.8s | 27.1 tok/s | +31% |
Takeaway
For Qwen3.5 2 B and larger, mixed-precision KV gives a 31–62% decode speedup at 64 k context. 0.8 B is too small to benefit —
optiq kv-cache's sensitivity pass correctly picks uniform 4-bit (no layer needs 8-bit protection), but on M3 Max even that's marginally slower than fp16 at this scale.
Per-layer KV configs (generated by
optiq kv-cache --target-bits 4.5)| Model | Full-attn layers | Config | Avg bits |
|---|---|---|---|
| Qwen3.5-0.8B | 6 of 24 | 6 @ 4-bit | 4.00 |
| Qwen3.5-2B | 6 of 24 | 6 @ 4-bit | 4.00 |
| Qwen3.5-4B | 8 of 32 | 7 @ 4-bit + 1 @ 8-bit (layer 3) | 4.50 |
| Qwen3.5-9B | 8 of 32 | 7 @ 4-bit + 1 @ 8-bit (layer 3) | 4.50 |
Why layer 3?
In Qwen3.5's hybrid architecture, layer 3 is the first full-attention layer (layers 0, 1, 2 are linear-attention). It's consistently the most KV-sensitive layer across both 4 B and 9 B — and protecting it at 8-bit also happens to flip it onto
mx.quantized_matmul's fast path on Apple Silicon. Quality and speed point the same direction.
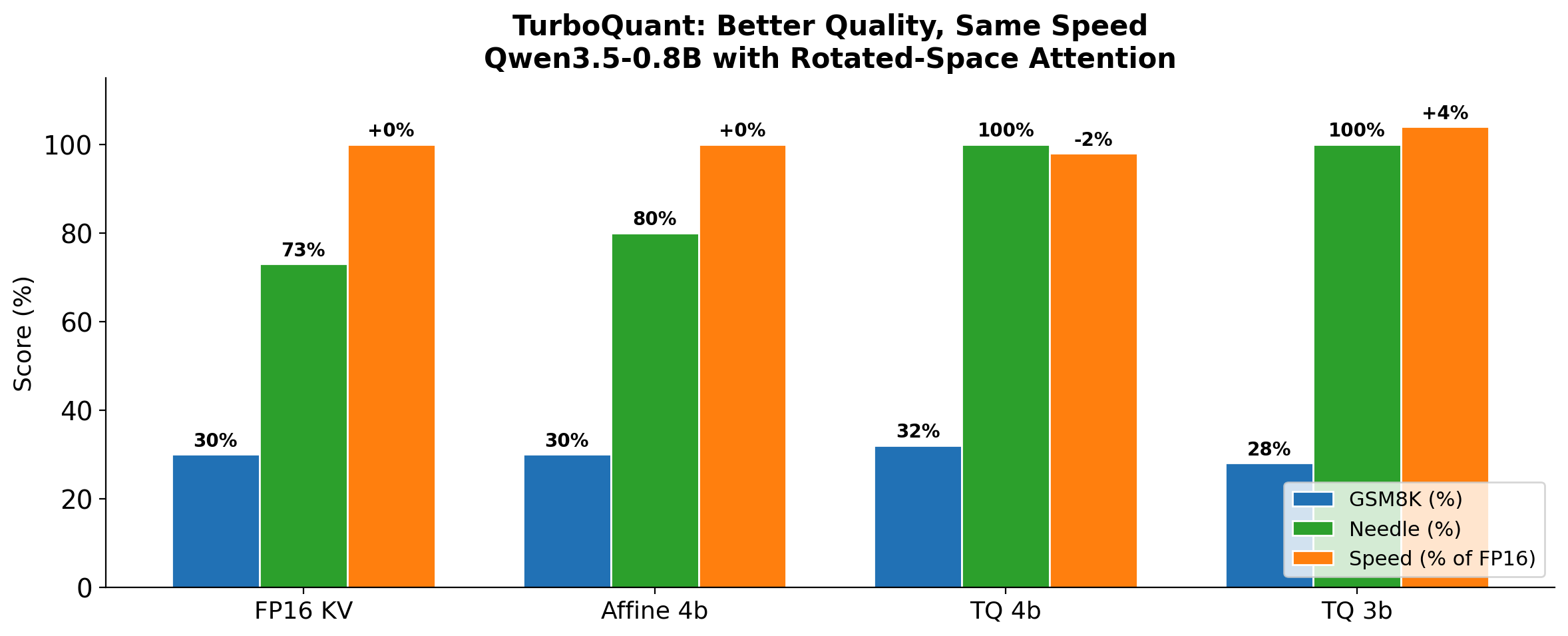
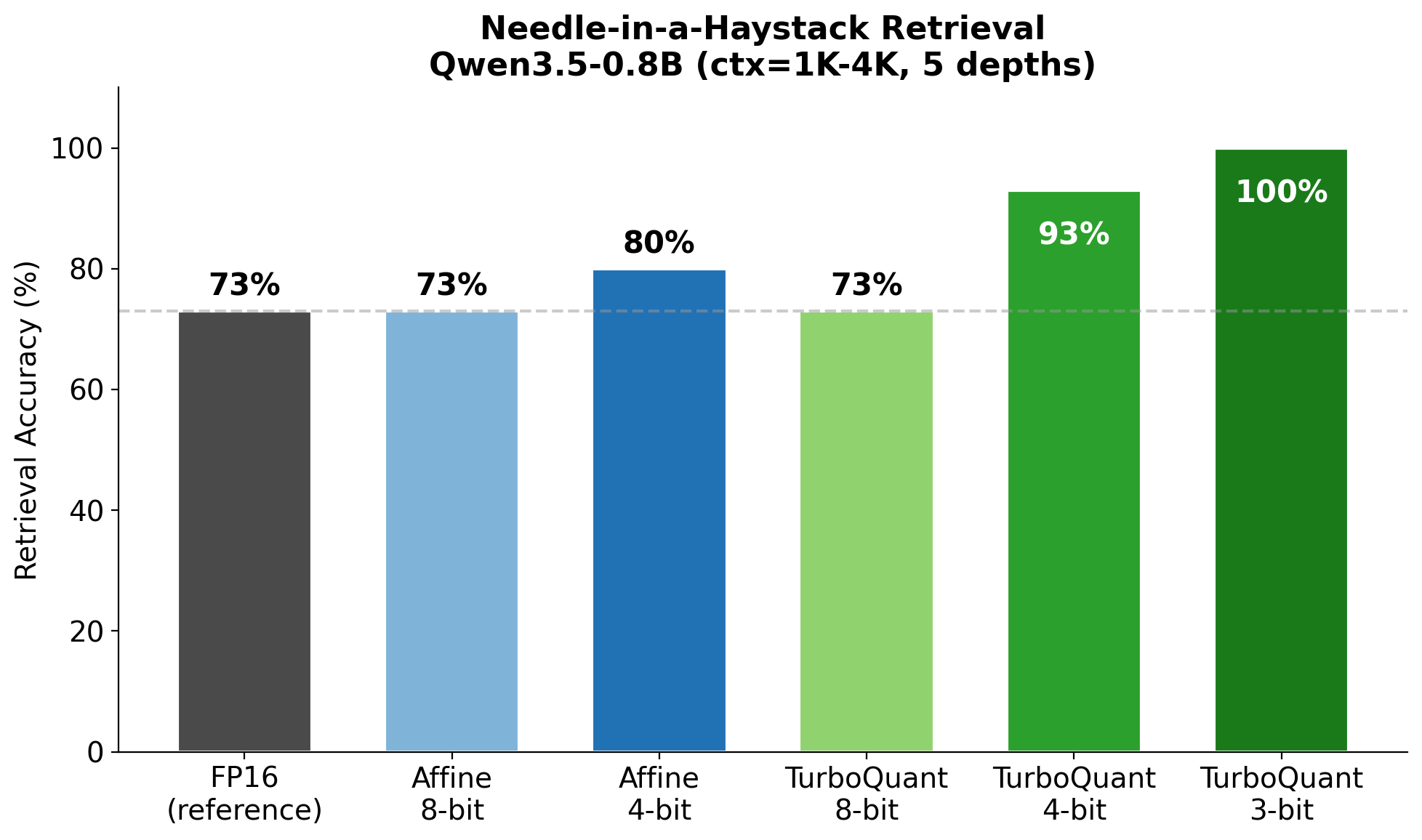
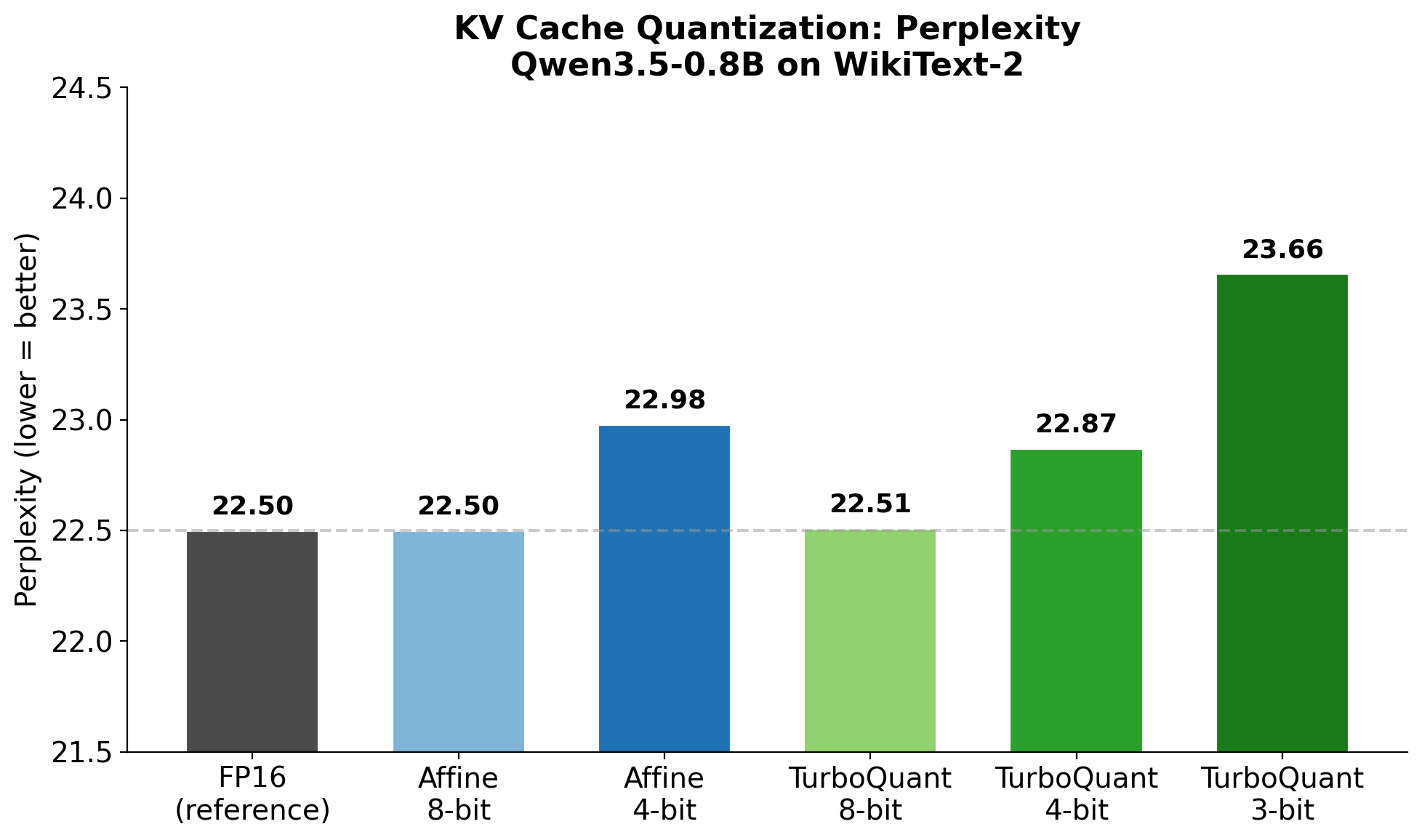
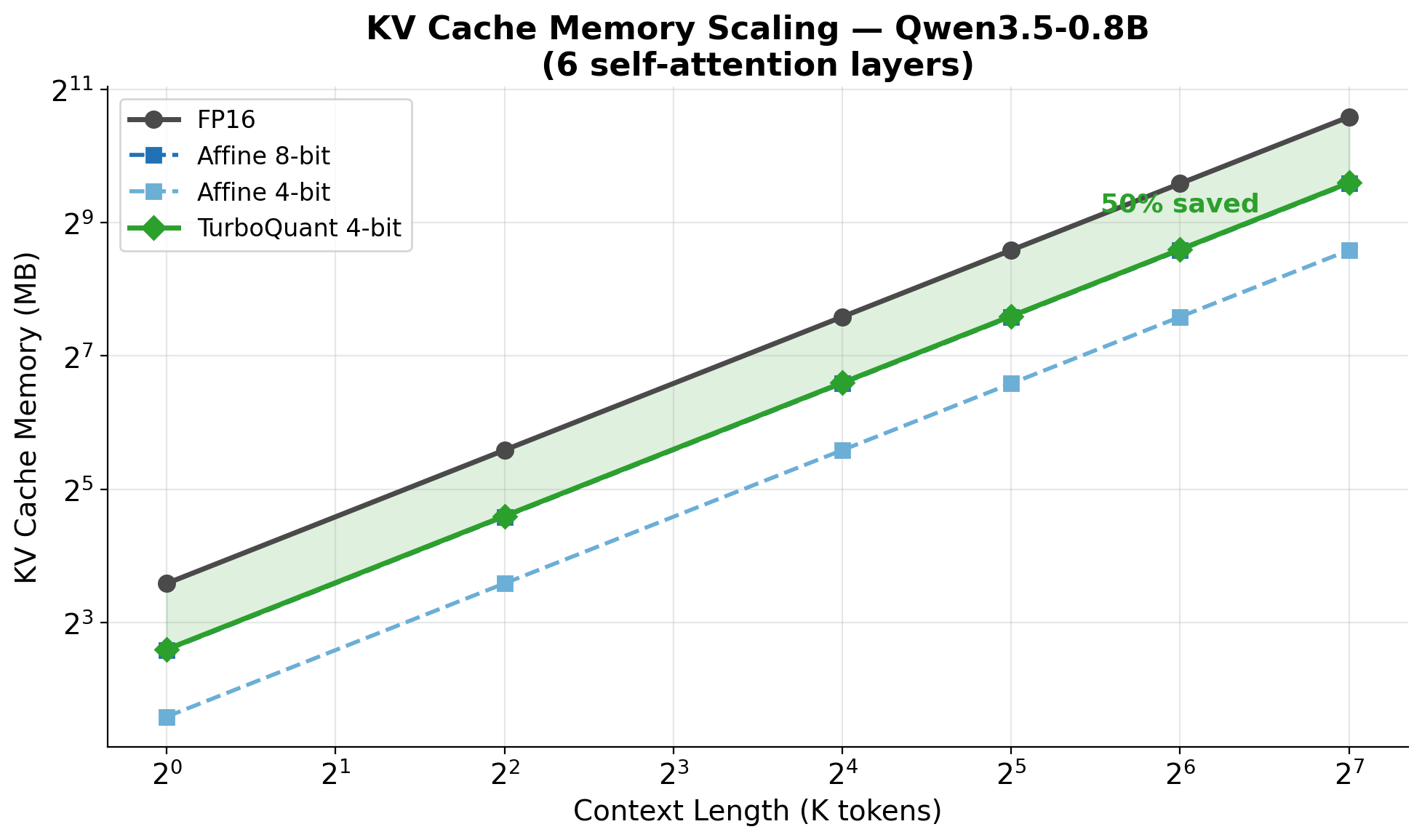
03 TurboQuant research
Rotated-space attention vs affine KV.
The research path: rotation-based vector quantization that preserves inner products for attention. Compared against mlx-lm's affine QuantizedKVCache.