Five threads. One signal.
mlx-optiq ships as one library, but it's really five experiments stitched together by a single observation: per-layer sensitivity is the dominant signal for almost every quantization decision worth making. Each thread is its own pipeline you can run from the CLI.
Bits where they matter, not where they're cheapest.
Uniform 4-bit treats every layer the same. Some take that hit cleanly; others fall apart. mlx-optiq measures which is which (KL divergence on calibration data) then allocates bits by greedy knapsack on KL-reduction-per-bit.
$ optiq convert Qwen/Qwen3.5-9B \ --target-bpw 4.5 \ --candidate-bits 4,8 \ --reference auto
The KV cache is its own sensitivity problem.
Per-layer KV sensitivity is the analogue of weight sensitivity, run at serving time. Layer 0's KV is often 56× more sensitive than the average layer — uniform 4-bit KV is catastrophic. Per-layer measurement and assignment solves this.
# 1. Measure per-layer KV sensitivity $ optiq kv-cache mlx-community/Qwen3.5-9B-OptiQ-4bit \ --target-bits 4.5 --candidate-bits 4,8 \ -o ./kv/qwen35_9b # 2. Serve with the per-layer config $ optiq serve --model mlx-community/Qwen3.5-9B-OptiQ-4bit \ --kv-config ./kv/qwen35_9b/kv_config.json \ --max-tokens 32768
mx.quantized_matmul on Apple Silicon handles the 8-bit fast path more efficiently than 4-bit. Protecting one sensitive layer at 8-bit (while the rest stay 4-bit) flips that layer's attention onto the faster kernel — and because it's the KV-sensitive layer, output quality stays preserved. Quality and speed point the same direction.
Rotation preserves inner products. Affine quantization doesn't.
For quality-critical KV compression beyond mlx-lm's affine path: vector quantization on a random orthogonal rotation preserves the attention dot products. Rotated-space attention then avoids the per-key dequant that naive rotated quantization would incur — O(d²) fixed cost instead of O(seq_len × d²) per token.
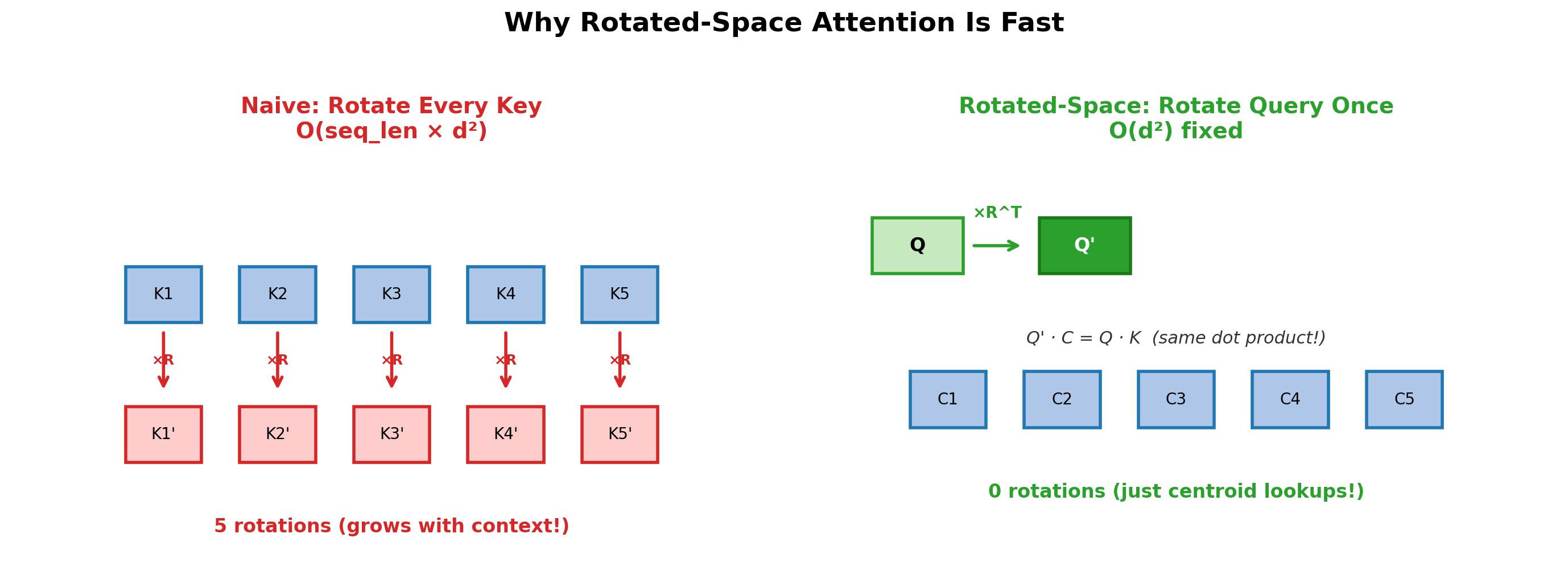
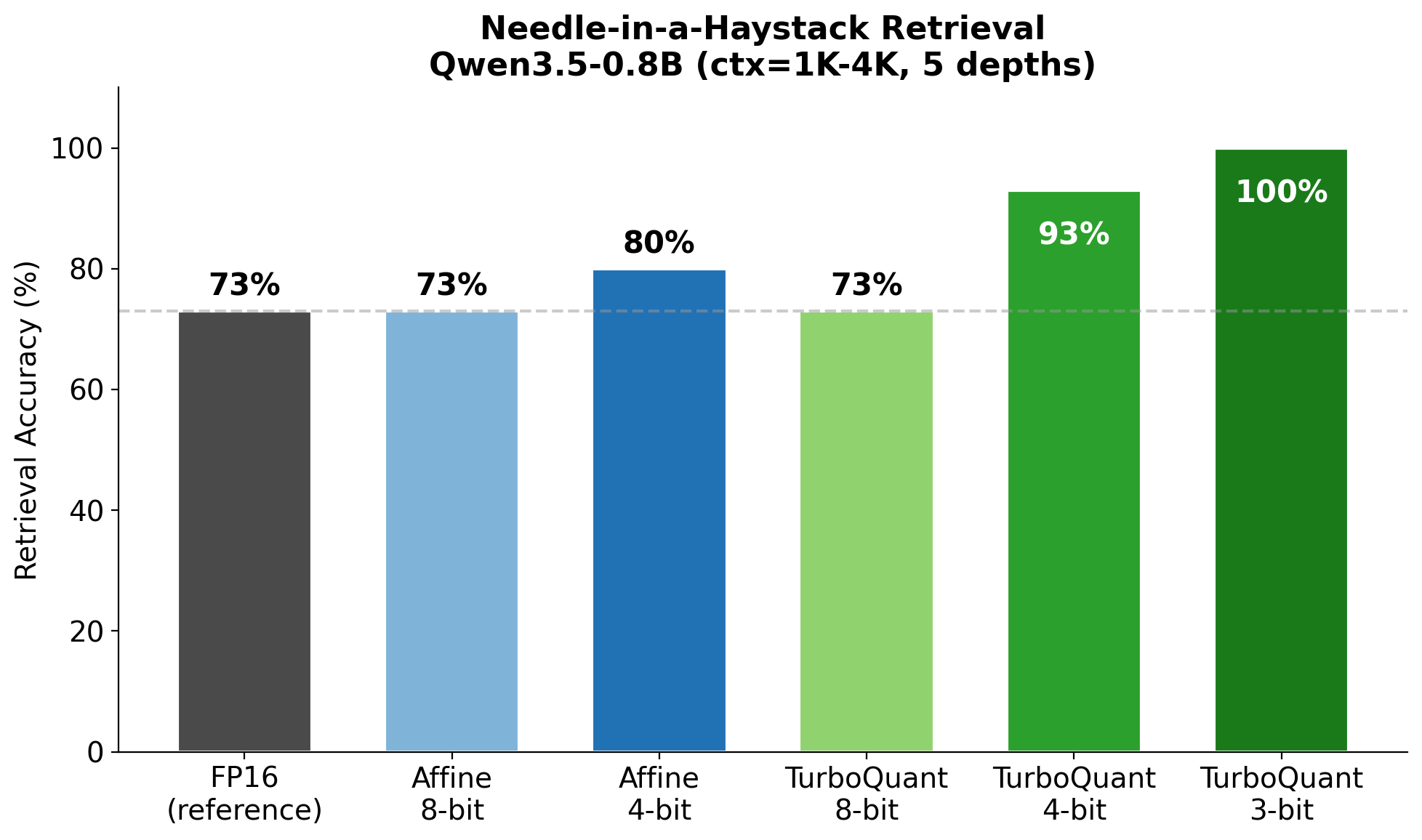
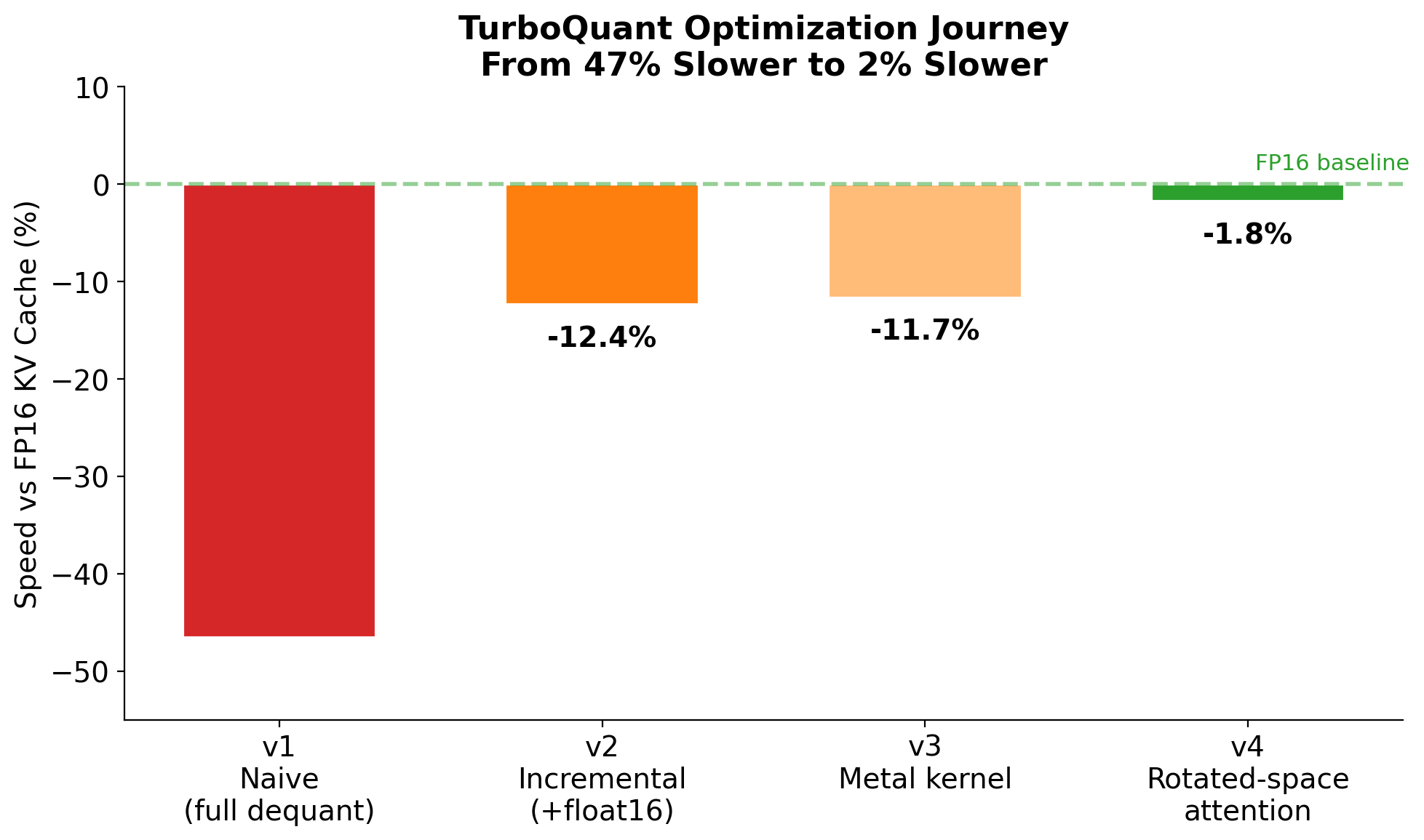
optiq serve currently uses mlx_lm.models.cache.QuantizedKVCache (affine) for its mixed-precision serving path because that's what integrates with the fused mx.quantized_matmul kernel. A fused-TurboQuant serve path is on the roadmap.
from optiq.core.turbo_kv_cache import ( TurboQuantKVCache, patch_attention, ) patch_attention() cache = model.make_cache() for i, layer in enumerate(model.layers): if hasattr(layer, "self_attn"): cache[i] = TurboQuantKVCache( head_dim=layer.self_attn.head_dim, bits=4, seed=42+i, )
Adapter rank, allocated by the same signal as bits.
Standard LoRA uses uniform rank across every adapted layer. mlx-optiq already knows which layers are sensitive — they got more bits during quantization. optiq lora train reuses that signal to give sensitive layers higher adapter rank at the same total budget.
# by_bits scaling: 8-bit layers get 2× the rank of 4-bit layers $ optiq lora train mlx-community/Qwen3.5-9B-OptiQ-4bit \ --data ./my_training_data \ --rank 8 --rank-scaling by_bits \ --iters 1000 -o ./my_adapter # Inspect the per-layer rank distribution $ optiq lora info ./my_adapter
--rank-scaling by_bits, a 4-bit layer gets the base rank (say 8) and an 8-bit layer gets 2× that (rank 16) at roughly the same total parameter budget. Adapter output is PEFT-compatible (adapter_config.json + adapters.safetensors) plus an mlx-optiq sidecar (optiq_lora_config.json) that records the per-layer rank distribution. See the fine-tuning guide for the empirical training-ceiling map across all 10 supported models.
N adapters on one base. Switch per request.
mlx_lm's stock load_adapters merges adapter weights into the base — fast but irreversible without a full reload. mlx-optiq ships a reversible mounted alternative that keeps adapter weights separate and gates them via a ContextVar the server flips per request.
from optiq.adapters.mount import ( mount_adapter_on_model, AdapterActivation, ) # Mount N adapters on one base, stays resident mount_adapter_on_model(model, "agent-A", "./adapter_a") mount_adapter_on_model(model, "agent-B", "./adapter_b") # Per-request: flip the ContextVar, generate, done with AdapterActivation("agent-A"): out_a = generate(model, tok, prompt=p, max_tokens=50) with AdapterActivation("agent-B"): out_b = generate(model, tok, prompt=p, max_tokens=50)